






從派克峰到 Bonneville 鹽灘,Lightning 的速度超越內燃機機車
Lightning Motorcycles 設計的純電動機車在各個領域都表現出色。瞭解 Vicor 電源模組如何助力這款新一代機車
垂直電源方案可提供高達 100kA 的電流和多軌核心電壓傳輸
作者:Paul Yeaman, 應用工程高級總監
最近,基於 AI ASIC 處理器的新型集群超級運算機的引入,將電源傳輸網路的邊界提高到了幾年前從未想象過的水平。隨著電流水平接近 100kA/ASIC 集群的應用,需要在電力系統架構、拓撲、控製系統和封裝方面進行創新,以供應如此高的電流需求。由於功率水平不斷提高,采用 48V 電源總線進行功率傳輸至關重要。此外,日益緊湊的處理器集群應用限製了電源方案在處理器旁橫向擺放的可行性,因此需要一種新的電源方案來解決問題。
Vicor 48V 直接至負載(<1V)分比式架構(FPA™) 與常見的 48V 中間總線架構(IBA)不同,IBA 還是傳統的由一個中間母線轉換器和多相 PoL 穩壓器組成,而 FPA 則通過創新解決方案獨特地解決了集群處理器系統面臨的每一個電源傳輸難題,它還支持電源方案在處理器對應面垂直擺放的方式,這種垂直電源傳輸方式(VPD)對於向此類集群系統提供高電流至關重要。
集群式 ASIC 系統采用緊密封裝,以達到所需的高速帶寬,從而實現 AI 訓練工作負載(如自動駕駛)所需的萬億次處理性能。集群中的每個處理器本身可能需要 600 到 1000 安培的電流,所以即使是單個處理器加速卡上邊,如果電源方案的擺放位置不接近處理器的電源引腳,也會帶來嚴重的 PCB 或基板阻抗損失,從而帶來電源傳輸功率損耗的挑戰。
此外,GPU 和專門的 AI 處理器已經采用 7nm、5nm 工藝製程,很快將使用 3nm 矽工藝節點,從而實現人工智慧(AI)的快速發展。這些工藝節點的標稱核心工作電壓目前在 0.75 至 0.85V 之間。為了達到 AI 要求的工作性能,需要把 GPU 和處理器先安放在加速卡上,然後將加速卡群集到基於服務器機架的系統中,資料中心和高性能運算機的每個機架上有 4 或 8 個加速卡。然而,最近來自 Cerebras 和特斯拉(Tesla)的介紹顯示了另一種將人工智慧 ASIC 本身進行集群的方法,這種方法可以生成極大算力、極高功率密度的超級運算機,但同時也帶來了對電源傳輸方面的嚴峻考驗和對熱管理/冷卻方面的挑戰。
對於電源傳輸來說,ASIC/GPU 集群已經沒有單處理器或雙處理器 AI 卡那樣的橫向電源傳輸空間,其所使用的高速 I/O 信號對大電流開關雜訊(即硬開關多相降壓(buck)穩壓器工作時產生的雜訊)極為敏感。所以將硬開關多相電源方案移動到更靠近處理器的位置會帶來更多的電流開關雜訊,這種情況下,電源方案設計既要滿足雜訊敏感 I/O 信號的要求,又要盡量降低 PDN 值就是一個巨大的挑戰。在 40–60A/ 相的典型設計值下,給每個 AI ASIC 或 GPU 提供高峰值電流(很多情況下每個 AISC 電流需求大於 1500A)所需的多相電源方案數量很容易超過 30 相,在這種應用場景下,傳統的橫向電源(多相 buck 方案)幾乎是難以實現的。
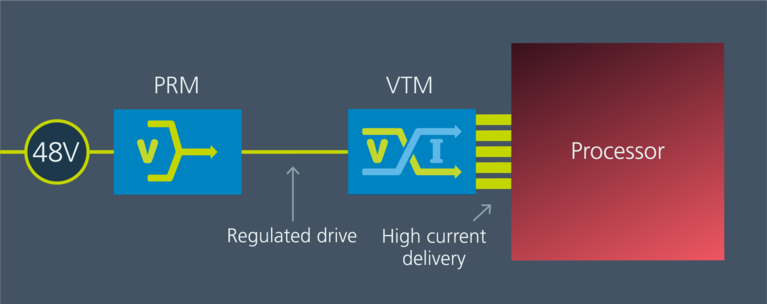
分比式架構(FPA)的基本原理是將電源轉換器分為兩個主要功能,分別對每個功能進行優化,然後將這些功能作為一個系統來實現。這兩個功能分別是穩壓和電流倍增。
穩壓器的效率與所做的工作成反比——工作越多,效率越低。穩壓器的輸入電壓和輸出電壓越接近,執行的工作就越少,效率就越高。憑借分比式架構在系統中的位置優化,可以使穩壓器的輸入至輸出電壓差最小化。PRM™ 穩壓器采用零電壓開關(ZVS)升降壓(buck-boost)拓撲結構,在輸入和輸出電壓差較小的情況下具有高效率。ZVS 大大降低了開關損耗,實現了高頻操作,大大減小了轉換器的尺寸。PRM 通常將 40 至 60V 的輸入電壓調節為 30 至 50V 的輸出電壓。
PRM 之後是第二級,執行電壓降壓和電流提升功能。這是使用正弦振幅(SAC™)拓撲結構的 VTM™ 電流倍增器模組來實現的。VTM 的特性可以看作是一個理想的變壓器,其輸入和輸出電壓通過一個固定比率關聯,且在超過 1MHz 工作頻率時還能保持很低的阻抗(數百 µΩ) 。
由於 VTM 中沒有儲能裝置,所以只要保持足夠的冷卻,它就可以提供足夠大的能量。這使得 VTM 的功率容量與處理器的熱容量相匹配。
SAC 拓撲使用零電壓和零電流開關控製系統,這進一步降低開關雜訊和功率損耗。
圖 1: PRM™ 和 VTM™ 是 FPA 的組成部分。PRM 根據系統輸入電壓範圍和功率要求選擇;VTM 根據輸出電壓範圍和電流要求選擇。PRM 可安裝在系統中任何方便擺放的位置;VTM 應安裝在盡可能靠近處理器核心的位置。
PRM 和 VTM 一起構成 FPA 的功能模組:一個專門用於穩壓,另一個專門用於電壓轉換和電流倍增。
雖然用於實現高性能穩壓器的拓撲結構和架構很重要,但封裝技術同樣重要。Vicor SM-ChiP™ 封裝將所有無源器件、磁性器件、MOSFET 和控製器集成到一個模組中。此外,該封裝設計能夠在有效地供應大電流的同時,以最低的熱阻抗便於模組冷卻。許多 SM-ChiP 器件外表面的大部分地方都有接地金屬屏蔽。這不僅有助於冷卻,還可以屏蔽高頻寄生電流雜訊,防止其在器件外部傳播。
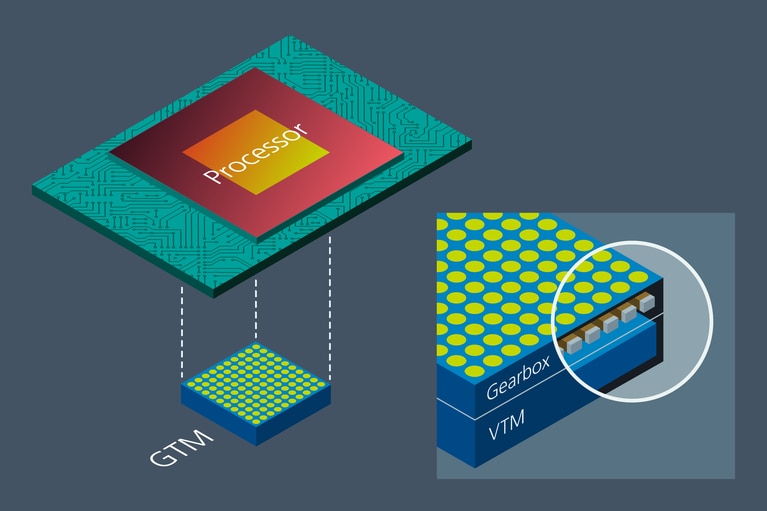
對於大型的,集群處理器陣列采用傳統的橫向電源傳輸方式幾乎是不可能的。集群處理器電源的最好解決方案是垂直電源傳輸方案(VPD)。在 VPD 中,電流倍增器直接位於主板另一側的處理器下方,通過縮短電流通過主板的距離,顯著降低了 PDN 損耗。VPD 需要兩個關鍵特性來實現此功能。
圖 2: 垂直電源傳輸方案 GTM™ 搭配電流倍增器置於處理器下方,最大限度地提高電源傳輸性能。垂直電源傳輸(VPD)解決方案還為包括更高 I/O 路由、板載內存或更緊密的處理器集群在內的方案設計大大減少了外圍器件應用數量。
首先,垂直電源方案(VPD)應該在處理器的正下方區域,那裏包含了很多高頻電容器,它們是將特高頻電流(>10MHz)與系統其余部分解耦所必需的。其次,為了獲得最大效率, VPD 解決方案的電流輸出位置和樣式必須跟處理器上的電流輸入位置和樣式鏡像一致,這樣才能夠實現真正的大電流「垂直」供電。
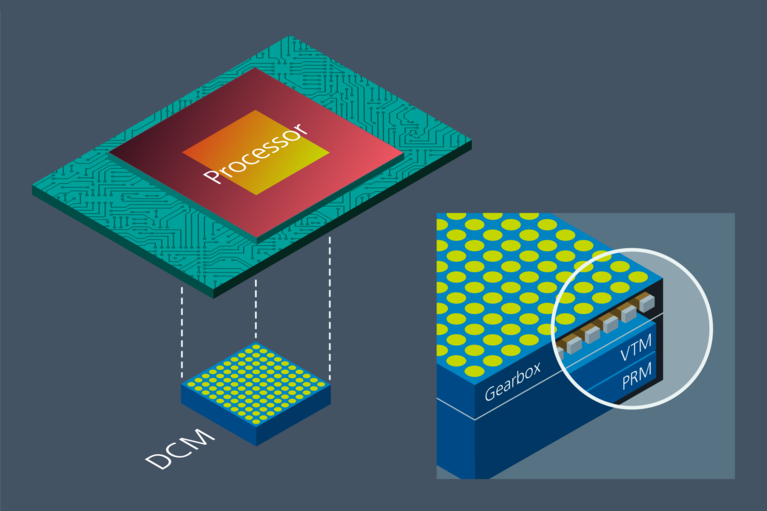
為了實現這些功能,Vicor VPD 解決方案是一個由三層組成的集成模組:下層是一個 Gearbox,中間層是 VTM™ 電流倍增器陣列,上層是 PRM™ 穩壓器,這樣的三層組成了一個完整的 VPD 解決方案,我們稱之為 DCM™。Gearbox 執行兩個功能:一是包含高頻去耦電容,二是把來自 VTM 的電流重新分配形成與上面的處理器鏡像一致的模式。VTM 陣列的大小取決於處理器輸入電流要求,PRM 的大小取決於總的功率需求。如果 GPU 或 ASIC 需要多個電源軌,則 VTM 層和 PRM 層可以分別使用獨立的 PRM 和 VTM 來實現,其大小可以滿足每個特定軌的電流和電壓要求。
圖 3: Vicor DCM™ 是針對 ASIC 集群的在一個先進封裝中實現的完整 48V 至負載 VPD 解決方案。PRM™、VTM™ 和模組的 gearbox 層提供穩壓、電流倍增、去耦電容和引腳到引腳的封裝匹配。
Vicor FPA™ 架構、ZVS 和 ZCS 控製系統、高頻 SAC™ 電流倍增器拓撲與 SM-ChiP™ 封裝技術提供了完善 VPD 的所有要素。它解決了低雜訊、集群式電源傳輸的難題,同時以高效率和熱適應能力強的電源模組封裝簡化了冷卻和熱管理機械設計。VPD 解決方案允許處理器通過集群進行高速海量資料分析,從而完善訓練模型,並將機器學習提升到顯著更高的水平,從而成為高性能 AI 系統的真正推動者。
AI 和機器學習正處於成長的初級階段,這列火車只會隨著歲月的流逝而加速。這種加速需要更快地處理更復雜資料的解決方案。基於 AI ASIC 處理器的新一代超級運算機將比傳統超級運算機需要更大的功率。一種新的、創新的電源傳輸方案是 AI 實現承諾的唯一途徑。它需要電源系統架構、拓撲、控製系統和封裝協同工作,以滿足不斷增加的高電流需求,利用電流倍增器的垂直供電方案是首選的解決方案。它是一種經過驗證的成熟方案,可以滿足當今對高性能運算的需求,並且可以輕松擴充以跟上未來的需求。它結構緊湊、效率高,可以將 PDN 功率損失降低 50% 以上。
本文 最初由《電子設計》發表。
Paul Yeaman 與行業中的科技領導者廣泛合作,開發和實施了系統中領先的電源解決方案,這些解決方案滿足行業中最嚴苛的電源需求。由於經常接觸新技術帶來的電源挑戰,Paul 瞭解電源行業的廣泛趨勢,並致力於確保創新者能够綜合電源解決方案以滿足這些需求。Paul 在電力電子行業的設計和應用工程領域有 20 多年的經驗。
Paul Yeaman, 應用工程高級總監
從派克峰到 Bonneville 鹽灘,Lightning 的速度超越內燃機機車
Lightning Motorcycles 設計的純電動機車在各個領域都表現出色。瞭解 Vicor 電源模組如何助力這款新一代機車
HIRO 利用高效能微型資料中心將歐洲推向前沿
從支持腦外科手術到在節省電力的同時推動智慧工廠的發展 —— HIRO 正在以創新的運算理念推動歐洲向邊緣發展
高效能運算電源的常見問題
高效能運算中 Vicor 電源解決方案的常見問題彙編
Vicor 在 Tech Taipei 上展示了電流倍增器技術如何最大限度提高運算效能
瞭解使用電流倍增技術最大限度提升運算效能的優勢


