By Doug Ping, Sr. Principle Applications Engineer
The increasing complexity and variety of compute workloads demand immense processing capabilities. Whether used in a cloud data center or on-premise, a new breed of processors is able to increase throughput and reduce latency. However, processor advances are pushing power delivery boundaries. As a result, power is often limiting the ability to reap top processor performance.
Data centers running hot with demand
The recent pandemic drove a surge in online shopping, media streaming and home working, with significant hyperscale service and retail providers expanding their capacity. However, for a more complete picture of data center growth, it should be set against a backdrop of several other drivers. The major technology-driven trends experienced in the last decade include the internet of things (IoT), artificial intelligence (AI), machine learning (ML) at the edge, and the exponential growth of operational technology (OT) workloads. Industrial operational performance improvement initiatives such as Industry 4.0 caused the dramatic rise of OT deployments. These factors necessitated more compute capacity, but they have also led to more diverse and demanding workloads.
There is an increasing demand for data centers to offer a flexible and scalable compute infrastructure capable of supporting highly dynamic workloads to provision cloud or on-premise services. The nature of some of the compute tasks demanded by recent trends involves low latency, spiking neural network algorithms and search acceleration. Specialized and highly optimized processing devices such as field-programmable gate arrays (FPGAs), graphics processing units (GPUs) and neural processing units (NPUs), once rarely used in a data center, have now become commonplace. Also, a new breed of application specific integrated circuits (ASICs), such as a clustered AI neural network inference engine, are in demand for high performance computing tasks.
The advances of processor technologies enable high performance computing to stretch the boundaries of task throughput, offering the agility to accommodate more workload diversity. However, technology gains often depend on other aspects of a system to advance together.
Technology trends increasing compute performance, underscore thermal challenges
In the semiconductor industry, change is inevitable. No sooner has a new, smaller silicon process node come into production than the next iteration is not far behind. Smaller geometries permit fabricating more individual semiconductor gates in a given space. Although 65nm and 55nm process nodes are still routinely used for many integrated circuits (ICs), high-performance computing devices such as ASICs, FPGAs, GPUs and NPUs are typically based on process nodes of 12nm or less, with 7nm and 5nm becoming increasingly popular. Already, customers are lining up for highly sophisticated high-performance processors using the 3nm process node.
Increasing the density of individual gates by reducing their dimensions highlights the constraints of managing the thermal characteristics of new processors. Reducing gate working voltage, a process called voltage scaling, helps reduce the heat dissipation of each transistor, but thermal management of the complete package remains paramount.
Typically, a high-performance processor will run at its maximum clock rate until thermal limits require throttling it back. Voltage scaling has seen core voltages drop to 0.75V for the most sophisticated 5nm process node-based devices and will fall further to a predicted 0.23V for 0.65V process node. To further complicate the power delivery challenge, many devices require multiple rails of different voltage levels, sequenced carefully to avoid permanent damage.
With the hundreds of billions of transistors typically found in a leading-edge GPU, the current demands become immense, running into the many hundreds of amps. A 1,000A requirement is not uncommon for a clustered AI processor. The current trend is that a processor's power consumption doubles every two years (Figure 1).
Another aspect of delivering power to such power-hungry devices is that their workloads can vary in a microsecond, potentially producing huge transients across the power delivery network (PDN).
Figure 1: Power delivery and power efficiency has become the largest concern in large scale computing systems. The industry has witnessed a dramatic increase in power consumed by processors with the advent of ASICs and GPUs processing complex AI functions. Rack power has also subsequently increased with AI capability being utilized in large scale learning and inferencing application deployments. In most cases, power delivery is now the limiting factor in computing performance as new CPUs look to consume ever increasing currents. Power delivery entails not just the distribution of power but also the efficiency, size, cost and thermal performance.
Power delivery challenges
As highlighted, the advances in semiconductor process technologies introduce several challenging conditions for the PDN. However, not all of them are technical. For example, the physical size of these leading-edge processing devices occupies a considerable proportion of available board space. A complication is that the board space is typically limited to an industry-standard form factor.
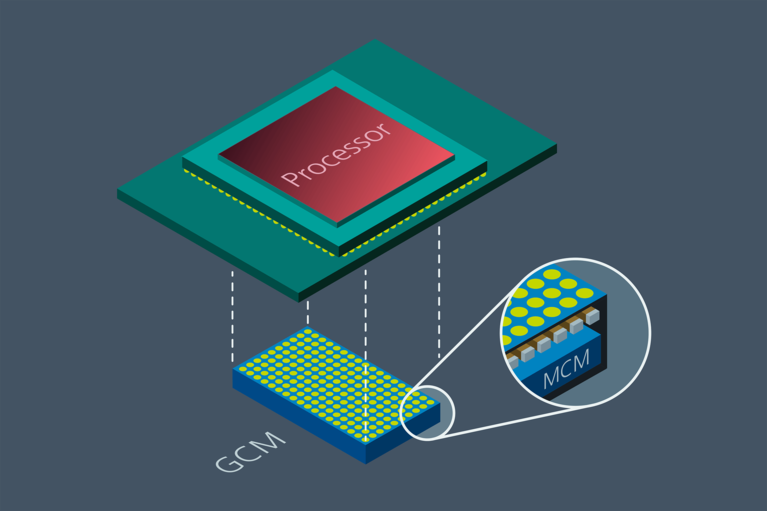
To further exacerbate the constraints placed on the board size, the nature of high performance compute devices requires supporting ICs, such as memory and optical transceivers placed close to the processor. This approach also applies to the point-of-load (PoL) power regulators due to the dramatic increases in current consumption and the reduced core voltages. The impact of PCB trace resistance with high currents creates I2R losses with a discernible voltage drop sufficient to impact processor performance, or worse, result in erratic behavior. PoL regulators also need to be highly power-efficient to prevent further thermal management complications (Figure 2).
Figure 2: VPD further eliminates power distribution losses and VR PCB board area consumption. VPD is similar in design to the Vicor LPD solution, with the added integration of bypass capacitance into the current multiplier or GCM module.
The combination of spaceconstrained boards and the need to mount regulators close to the processor stipulates a new and innovative approach to architecting the network PDN.
Powering the processor: PDN becomes a limiting factor
As processor technology continues to evolve, architecting an efficient PDN presents a set of three significant and interrelated challenges for power systems engineers.
Increasing current density
Leading-edge, high-performance processors can consume hundreds of amps. Getting sufficient power capability to the processor not only involves the physical constraints of where to place point-of-load converters, but complex decisions in PCB track routing power to the converter from edge connectors. High-voltage transients resulting from extremely dynamic workloads can interfere with other system components.
Improving power efficiency
There are two factors influencing power efficiency: I2R losses and conversion efficiency. PCB tracks are ideal for routing low-voltage signals and digital logic, but for high currents, no matter how short, they can represent significant resistive losses. These I2R losses lower the voltage supplied to the processor and can cause localized heating. With hundreds of other components on a processor card, there is a limit to the size of power supply tracks, so placing the converter as close as possible to the processor is the only viable alternative.
The converter’s power efficiency is an attribute of its design. The development of high-efficiency PoL converters is a specialized skill, involving an iterative approach to understanding losses in every component, from passives to semiconductors. As already highlighted, losses manifest as heat that requires dissipation. PoL converter module designers apply their design expertise and specialist knowledge to optimize the module’s internal design to achieve an isothermal package.
Maintaining PDN simplicity
Faced with PDN challenges, some power architects might opt to create a discrete PoL converter for the processor to carefully customize the PDN. However, despite the attraction this might represent as a viable solution, it actually creates additional complexity. A discrete design increases the bill of materials (BOM), introducing the need for sourcing more components and the associated logistics and supply chain costs. This approach also requires more engineering effort, increasing nonrecoverable expenses (NRE) and extends the development and testing timeline. Alternatively, a modular approach has been designed to optimize powering high-performance processors. Thermally adept, integrated power modules simplify the power design significantly, reducing the BOM, adding flexibility for changes and expediting development. Power modules are compact, power dense and easy to scale up or down.
A structured approach to solving high-performance compute power delivery challenges
To solve today’s common PDN challenges, Vicor offers two approaches that meet today’s most common situations.
Bridging legacy systems
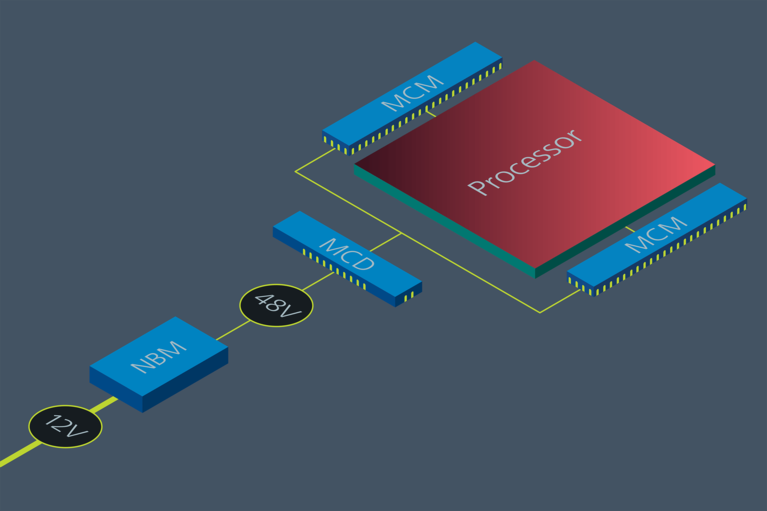
Connecting 12V to 48V systems. For legacy systems where more efficiency and power are needed, Vicor provides a simple option using a bidirectional NBM™ non-isolated bus converter. The NBM enables efficient conversion from 48V to 12V and vice versa, integrating a legacy board into a 48V infrastructure or the latest GPU
into a legacy 12V rack (Figure 3).
Figure 3: Connecting 12V to 48V systems. For legacy systems where more efficiency and power are needed, Vicor provides a simple option using a bidirectional NBM™ non-isolated bus converter. The NBM enables efficient conversion from 48V to 12V and vice versa, integrating a legacy board into a 48V infrastructure or the latest GPU into a legacy 12V.
48V to PoL Delivery
48V to point-of-load. The Vicor power-on-package (PoP) solution can reduce motherboard resistances up to 50x and processing power pin count more than 10x. Leveraging a Factorized Power Architecture (FPA™), Vicor minimizes the “last inch” resistances with two patented solutions, lateral power delivery (LPD) and vertical power delivery (VPD). Both enable processors to achieve previously unattainable performance levels to support today’s exponentially growing HPC processing demands.
The demands of data centers, edge compute and IoT are not subsiding. Big data needs to be processed quicker than ever before. Today’s maximum processing speeds will be too slow nine months from now. And power delivery will be the focus again. Finding new ways to increase throughput and reduce latency is a perpetual challenge. Identifying a solution that is flexible and scalable is the final piece that will complete the puzzle. This will minimize re-designs and ease the future modification. A modular approach accommodates all aspects of high-performance compute today and tomorrow.
Doug Ping has over 26 years of work experience in the power industry both in design and in applications, with 21 of those years at Vicor. Since 2007, his primary focus has been supporting power solutions for data center and autonomous vehicle applications.
Doug Ping, Sr. Principle Applications Engineer